Amazon Aurora- MySQL은 데이터베이스 워크로드를 통합(Database consolidation)하려는 고객에게 인기 있는 옵션입니다. Aurora MySQL은 고성능 상용 데이터베이스의 속도와 안정성에 오픈 소스 데이터베이스의 간편성과 비용 효율성이 결합된 관계형 데이터베이스 엔진입니다. 또한, 표준 MySQL 커뮤니티 에디션과 비교하여 최대 5배의 처리량을 제공합니다.
이 블로그 게시물에서는 대규모 통합 데이터베이스 워크로드를 위해 Amazon Aurora를 최적화하는 데 도움이 되는 몇 가지 지침을 제공합니다. 또한, “얼마나 많은 DB를 통합할 수 있습니까?” 혹은 “데이터 세트가 얼마나 커질 수 있습니까?”와 같은 일반적인 질문에 대한 답을 제공합니다. 이러한 질문이 간단하긴 하지만 답 또한 항상 간단한 것은 아닙니다. 답은 데이터 세트와 워크로드 패턴에 따라 크게 좌우됩니다.
데이터베이스 통합 정의
통합 사용 사례의 경우, 다음 차원에 초점을 맞춘 후 Aurora MySQL이 이러한 컨텍스트에서 어떻게 작동하는지를 자세히 설명합니다.
- 테이블 크기. 더 큰 테이블은 일반적인 통합의 결과입니다. 광고 기술, IoT 또는 소비자 애플리케이션 분야라면 대개 대규모 동종 애플리케이션 데이터베이스를 데이터 하위 집합이 포함된 여러 개의 샤드로 분할합니다. Aurora에서는 샤딩을 완전히 포기할 수는 없지만 더 적은 수의 샤드로 통합하여 운영 오버헤드를 줄일 수 있습니다.
- 테이블 수. 늘어난 테이블 수 또한 통합의 결과입니다. 이러한 결과는 테넌트 격리가 필요한 SaaS 애플리케이션, 즉 각 테넌트가 자체 데이터베이스 또는 테이블 세트를 사용하는 SaaS 애플리케이션에서 일반적으로 발생합니다. 이러한 유형의 멀티 테넌트는 더 적은 수의 더 큰 Aurora 클러스터로 함께 패키징되어 테넌트당 운영 비용을 줄입니다.
- 데이터베이스 사용률. 동시 연결 수 증가를 비롯하여 여러 지표에서 통합된 데이터베이스 워크로드 사용률이 증가합니다.
실제로 동일한 프로젝트에서 이러한 차원 중 몇 가지가 증가하는 것을 경험하게 됩니다. 다음 지침은 이러한 차원 전체에서 워크로드를 최적화하는 데 도움이 됩니다.
데이터베이스의 최대 크기
Amazon Aurora에는 몇 가지 최대 한도가 있습니다. 가장 눈에 띄는 것은 Aurora 클러스터의 최대 스토리지 볼륨 크기가 64TB라는 것입니다. 볼륨 최대 크기는 Aurora 클러스터에 물리적으로 저장할 수 있는 데이터 양에 대한 상한을 제공합니다. 또한, 개별 테이블 크기에 대한 상한도 제공합니다.
MySQL 호환 데이터베이스 엔진인 Aurora MySQL은 MySQL과 InnoDB 스토리지 엔진의 속성을 다수 상속받습니다. 이 중 일부가 효과적으로 통합할 수 있는 양에 영향을 미칩니다.
테이블 크기를 최적화하는 방법
Amazon Aurora는 16KiB 페이지를 사용하여 데이터를 저장합니다. 페이지는 테이블과 관련 인덱스의 컨테이너 역할을 하는 테이블스페이스로 그룹화됩니다. 기본적으로 Aurora는 테이블별로 또는 테이블이 파티션된 경우 테이블의 파티션별로 별도의 테이블스페이스를 사용합니다. 테이블스페이스에 주로 포함된 것은 다음과 같은 데이터 구조입니다.
- 테이블 레코드가 포함되어 있고 테이블의 기본 키 또는 고유 키로 정렬된 클러스터링된 인덱스. 두 키 모두 사용할 수 없는 경우, 일정하게 증가하는 내부 행 ID가 레코드를 식별하고 정렬하는 데 사용됩니다.
- 테이블의 보조 인덱스.
- 클러스터링된 인덱스 레코드에 적합하지 않은 가변 길이 필드에 대한 외부 저장 값(BLOB, TEXT, VARCHAR, VARBINARY 등).
앞의 테이블 아키텍처는 주어진 테이블에 저장할 수 있는 최대 행의 수가 정해져 있지 않다는 것을 의미합니다. 최대 행 수는 몇 가지 요인에 따라 달라집니다.
- 기본 키 또는 고유한 키 옵션에서 지원하는 최대 고유 값 수. 예를 들어 기본 키에 부호 없는 INT 데이터 유형을 사용하는 경우(일반적인 선택), 테이블에서 최대 232 또는 최소 42억 9천 개의 행을 지원합니다.
- 보조 인덱스의 수 및 크기.
- 클러스터링된 인덱스 레코드에 직접 또는 외부 페이지에 저장된 가변 길이 데이터 양.
- 데이터 페이지가 얼마나 효과적으로 사용되는지.
스키마 디자인 및 쿼리 패턴은 실제로 얼마나 효과적으로 테이블을 통합할 수 있는지를 결정할 때 행 수보다 중요한 요인입니다. 테이블의 행 수가 증가하면 클러스터링된 인덱스 및 보조 인덱스의 크기와 이러한 인덱스를 트래버스하는 데 걸리는 시간도 증가합니다. 따라서 쿼리 성능은 테이블 크기에 따라 감소합니다. 성능 저하를 좀 더 심층적으로 완화할 수 있는 몇 가지 모범 사례와 방법을 살펴보겠습니다.
1. 대량 레코드 포함 테이블을 위한 스키마 설계
쿼리 패턴 및 스키마의 컨텍스트에서 페이지당 레코드 밀도는 큰 테이블 크기에서 점점 더 중요해집니다. 가변 길이를 제외하고 Aurora MySQL의 최대 행 길이는 8KB에 약간 못 미칩니다(데이터 페이지의 절반). 데이터베이스는 페이지를 관리하여 성능 저하 없이 스토리지 효율성을 유지합니다. MySQL 커뮤니티 에디션의 InnoDB처럼 Aurora MySQL은 향후 쓰기 작업을 수용하고 페이지 분할 수를 줄이기 위해 페이지 일부를 채우지 않고 비워둡니다. 또한, 채우기 비율이 50% 이하로 떨어지면 페이지를 함께 병합하려고 시도합니다. 페이지가 완전히 채워지는 경우는 없으므로 항상 일정량의 스토리지 오버헤드가 발생합니다.
최적의 스키마 디자인은 유용한 오버헤드가 과도한 스토리지 낭비가 되지 않도록 보장하는 최선의 방법입니다. 이러한 낭비는 리소스 사용률과 지연 시간 증가로 이어지므로, 수용 가능한 성능 이상으로 워크로드에 부담을 줍니다.
효과적인 스키마 디자인을 위한 두 가지 매우 중요한 지침이 있습니다.
- 주어진 테이블 행의 모든 정보의 가치는 모두 같아야 합니다. 즉, 행의 모든 필드에 있는 데이터를 동일한 빈도로 쿼리하고 조작해야 합니다. 동일한 행에 사용 빈도가 다른 데이터를 저장하는 것은 비효율적입니다.
- 항상 주어진 열에 저장된 값을 나타낼 수 있는 가장 작은 데이터 유형을 선택하십시오. 개별 행 수준에서는 효과가 미비할 수 있지만, 잠재적으로 수십억 개의 행에서는 그 효과가 확대되어 현저한 차이를 보입니다.
스키마에 가변 길이 필드가 포함된 경우, Aurora MySQL은 가능한 많은 가변 길이 데이터를 클러스터링된 인덱스 레코드에 저장하려고 시도하며 나머지는 외부 페이지에 저장됩니다. 대규모 데이터 레코드는 데이터 페이지의 레코드 밀도를 낮추어 쿼리 성능을 저하시킵니다. 하지만 쿼리가 가변 길이 필드를 비롯하여 모든 레코드 데이터(읽기 및 쓰기)에 지배적인 영향을 미치는 경우 여전히 대규모 레코드를 원할 수도 있습니다. 그런 경우가 아니라면 대규모 필드는 별도 테이블로 오프로드하는 것이 유용할 수 있습니다. 또는 데이터베이스가 아닌 Amazon S3와 같은 객체 스토어에 저장하는 것이 더 좋습니다.
인덱스는 쿼리 성능을 높이는 데 효과적입니다. 하지만 추가 비용이 발생하고 추가 스토리지와 메모리 공간을 소비하며 쓰기 성능을 저하시킵니다. 보조 인덱스 레코드는 열의 물리적 스토리지 좌표를 직접 가리키지 않습니다. 대신에 해당 열의 기본 키 값을 가리킵니다. 따라서 모든 보조 인덱스 레코드에는 해당 행의 기본 키 값 사본이 포함되어 있습니다.
이에 따라 복합 기본 키로 인해 더 큰 인덱스 레코드가 생기고 궁극적으로 스토리지 및 I/P 효율성이 떨어집니다. 필요한 인덱스만 사용하고 복합 인덱스에서 인덱스 선택은 왼쪽에서 오른쪽으로 이동한다는 것을 기억하십시오. 쿼리 패턴에서 해당 선택 규칙을 따르도록 허용하는 경우, 인덱스를 더 적은 수의 복합 인덱스로 대체하여 인덱스 수를 줄일 수 있습니다.
궁극적으로 효과적인 스키마 디자인을 사용하면 수용할 수 없는 성능을 경험할 필요 없이 더 많은 수의 행이 있는 테이블을 보유할 수 있습니다. 하지만 최대 행 수가 몇 개가 될지는 실제 데이터 및 해당 데이터와 상호 작용하는 방법에 달려 있습니다.
2. 대량 레코드 포함 테이블 쿼리
파티션(및 하위 파티션)은 대규모 테이블에서 성능 감소를 완화하는 도구입니다. 기본적으로 각 파티션은 별도의 테이블스테이스에 저장되므로, 파티션에는 파티셔닝 표현식에 정의된 대로 클러스터링된 인덱스, 보조 인덱스, 해당 특정 데이터 하위 세트의 외부 페이지가 포함되어 있습니다. 테이블당 최대 8,192개의 파티션 및 하위 파티션을 가질 수 있습니다. 하지만 파티션 수가 많으면 그 자체로 성능 문제가 발생합니다. 많은 수의 파티션을 사용하는 쿼리로 인해 메모리 사용률이 증가하고 성능 문제가 발생하는 것이 이에 포함됩니다.
파티션의 인덱스 구조가 더 작으므로 트래버스하는 것이 더 빠릅니다. 쿼리 패턴이 단일 파티션 또는 매우 작은 파티션 세트를 선택적으로 읽는 경우(파티션 프루닝(partition pruning)이라고 부르는 최적화 기능), 성능 이점을 누릴 수 있습니다. 하지만 예를 들어 파티션된 열이 포함되지 않은 조건자가 있는 쿼리처럼 일부 특정 파티션만 선택적으로 읽지 않는 쿼리는 속도가 더 느릴 수 있습니다. 파티션에서는 엔진이 하나의 더 큰 인덱스 대신 여러 개의 더 작은 인덱스를 트래버스해야 하므로 이 효과가 발생합니다. 따라서 파티션된 대규모 테이블의 성능 영향은 워크로드에서 파티션 프루닝 또는 파티션 셀렉션을 얼마나 효율적으로 활용하는지에 달려 있습니다.
대규모 테이블의 경우 정확한 통계가 쿼리 옵티마이저에 중요합니다. 정확한 통계는 쿼리 옵티마이저가 올바른 카디널리티로 가장 선별된 인덱스를 사용하도록 지원하므로 쿼리 성능이 향상됩니다. 기본적으로 Aurora MySQL은 20개의 임의 인덱스 페이지를 샘플링하여 통계와 카디널리티를 예측합니다. 하지만 매우 큰 테이블 또는 열 내 값이 균일하지 않은 테이블을 처리할 때는 이 개수로는 충분하지 않을 수 있습니다. 또한, 기본적으로 통계는 디스크에 유지되고 테이블의 상당 부분이 변경되면 자동으로 다시 계산됩니다. 10% 이상의 행에 영향을 미치는 DML(데이터 조작 언어) 작업을 예로 들 수 있습니다.
매우 큰 테이블에서는 이 정도 규모의 변경은 자주 발생하지 않으므로 시간이 지나면서 통계의 정확도가 감소할 수 있습니다. 따라서 임계점에 도달하고 쿼리 옵티마이저가 실행 계획을 변경하면 영향을 받은 쿼리의 성능이 시간이 지나면서 계속해서 또는 급격히 저하됩니다. 이것이 문제가 된다고 생각하는 경우, EXPLAIN 문을 사용하여 쿼리 실행 계획을 검토하여 예상되는 동작의 변경 사항을 찾아내십시오.
또한, 핵심 워크로드 쿼리의 예상 성능 기준선을 설정하고 시간이 지나면서 성능을 모니터링하는 것이 좋습니다. 느린 쿼리 로그는 특정 임계값을 초과하는 쿼리를 로깅하는 데 효과적이지만, 시간 경과에 따라 천천히 진행되는 성능 저하를 캡처하는 데는 효과적이지 않습니다. MySQL 5.6 호환 버전에서 지속적으로 쿼리 성능을 모니터링하려면 MySQL 성능 스키마를 사용하면 됩니다. 하지만 이 기능을 활성화하면 메모리 소비가 증가하고 전반적인 시스템 성능도 저하될 수 있습니다.
통계의 정확성을 개선할 수 있는 두 가지 메커니즘이 있습니다.
- 정보 스키마를 사용하여 관련 테이블에 대한 테이블 및 인덱스 통계의 경과 시간을 모니터링(
INNODB_TABLE_STATS및INNODB_INDEX_STATS)한 후ANALYZE TABLE을 실행하여 적절하게 통계를 업데이트합니다. - DB 인스턴스에 대한 DB 파라미터 그룹을 사용자 지정하고 샘플링되는 페이지 수를 늘리면 정확도가 증가합니다(아래 표 참조). 하지만 샘플링되는 페이지를 늘리면 통계를 계산하는 데 걸리는 시간 또한 늘어납니다.
| DB 파라미터 | 값 | 설명 |
| innodb_stats_persistent_sample_pages | 256 | 통계가 디스크에 유지되는 경우 샘플링된 페이지에 대한 글로벌 파라미터. 이 파라미터를 테이블별로 구성할 수도 있습니다. |
| innodb_stats_transient_sample_pages | 256 | 위에 있는 것과 비슷하지만 통계가 디스크에 유지되지 않는 경우 사용되는 글로벌 파라미터. |
3. 대규모 테이블의 데이터 스키마에 대한 변경 처리
DDL(데이터 정의 언어) 작업이 문제가 되려면 테이블이 얼마나 커야 합니까? 크기도 한 요인이지만 테이블이 얼마나 활발하게 사용되는지가 더 중요할 수 있습니다. 테이블이 초당 수천 개의 쓰기 작업을 지원하고 있다면, 상대적으로 레코드 수백만 개의 상대적으로 작은 테이블도 DDL 작업을 실행하기에 문제가 될 수 있습니다.
워크로드 또는 워크로드에 대한 업데이트가 빈번한 DDL 작업 및 스키마 변경에 의존하는 경우, 이러한 작업으로 인해 매우 큰 테이블을 사용할 수 있는 기능이 제한될 수 있습니다. 이 동작은 MySQL 커뮤니티 에디션이 작동하는 방식과 비슷합니다. 오프라인 DDL 작업은 데이터를 올바른 스키마의 새로운 테이블스페이스로 복사합니다. 따라서 적절한 여유 용량을 확보해야 합니다. 또한, 작업 범위에 따라 테이블이 잠기므로 일반 워크로드에 영향을 줍니다. 온라인 DDL 작업은(수행 가능한 경우) 테이블 데이터를 직접 변경합니다. 하지만 임시 스페이스에서 테이블에 대한 새로운 쓰기를 버퍼링하므로 해당 쓰기가 다시 병합될 때만 테이블이 잠깁니다. 장기 실행 온라인 DDL 작업을 수행하는 테이블에 대한 매우 많은 수의 쓰기를 생성하는 워크로드의 경우, 병합할 변경 사항의 양이 상대적으로 많습니다. 이 크기는 병합 단계 잠금에 걸리는 시간일 길어지는 데 영향을 줍니다. 극단적인 경우, 테이블 변경 작업이 완료되기 전에 임시 스페이스가 고갈되어 실질적으로 온라인 DDL 작업이 완료되지 못할 수 있습니다.
Aurora MySQL은 빠른 DDL을 지원하므로, 거의 즉각적인 작업으로 테이블 끝에 nullable 열을 추가할 수 있습니다. 이 기능은 앞에서 설명한 DDL의 단점 일부를 완화하는 데 도움이 됩니다. 일반 DDL 또는 빠른 DDL 작업으로는 효율적으로 처리할 수 없는 DDL 작업의 경우, Percona 온라인 스키마 변경 도구를 사용하여 이 작업을 실행하는 것을 고려해 볼 수 있습니다. 이 도구를 사용 사례에 적용하면, 덜 파괴적인 방법으로 DDL 작업을 수행할 수 있지만 매우 큰 테이블에서는 작업이 더 오래 걸립니다.
다수의 테이블을 최적화하는 방법
통합된 워크로드로 인해 많은 수의 테이블이 Aurora 클러스터에 저장될 수 있습니다. 실제로 하나의 Aurora 클러스터에 통합될 수 있는 적정 테이블 수는 워크로드와 액세스 패턴에 따라 달라집니다.
파일 시스템 속성이 데이터베이스 확장성(테이블 크기와 수)을 제한하는 MySQL 커뮤니티 에디션과는 달리 Aurora MySQL은 특별히 구축된 분산 로그 구조의 스토리지 서비스를 사용합니다. 따라서 파일 시스템의 상속된 한계를 완화하기 위해 MySQL에서 사용자 지정 테이블스페이스 구성을 사용하는 수많은 이유가 Aurora에는 적용되지 않습니다. 운영 측면 또는 장애 복구 측면에서, 테이블 수가 많다고 해서 파일 시스템에 영향을 주지는 않습니다. Aurora 사용자 지정 DB 클러스터 파라미터를 사용하여 inndb_file_per_table 옵션을 비활성화할 수 있지만, 권장하지는 않습니다. 성능 또는 복구 시간에 더는 영향을 주지 않기 때문입니다.
하지만 Aurora에 많은 수의 테이블이 있으면 메모리 사용률에 영향을 줍니다. 기본 파라미터가 설정된 Aurora 클러스터의 메모리 사용량은 다음과 같습니다.
| 사용된 DB 인스턴스 메모리 | 소비자 |
| 3/4 | 최근에 액세스된 데이터 페이지를 저장하는 버퍼 풀(페이지 캐시). DB 파라미터 그룹에서 이 구성을 변경할 수 있습니다. 하지만 버퍼 풀의 크기를 줄이는 것은 일반적으로 바람직하지 않습니다. 버퍼 풀 효율성을 추적하는 관련 Amazon CloudWatch 지표는 버펄 풀 캐시 적중률과 스토리지에 대한 읽기 IOPS입니다. |
| 1/24 | 쿼리 캐시. 버전 5.7.20에서 쿼리 캐시가 사용 중단되고 비활성화된 MySQL 커뮤니티 에디션과는 달리 Aurora는 업그레이드된 쿼리 캐시를 사용합니다. 이 쿼리 캐시에는 커뮤니티 에디션에 구현된 한계가 발생하지 않습니다. 쿼리를 캐시할 수 없는 것이 확실하고 다른 버퍼와 캐시에서 사용하도록 메모리를 회수하려는 것이 아니라면 쿼리 캐시를 활성화된 상태로 두는 것이 좋습니다. |
| 나머지 | 나머지 가용 메모리(약 20.8%)는 연결 또는 세션, 운영 체제, 관리형 서비스 프로세스에 특정되거나 전역적인 데이터베이스 엔진 버퍼 및 캐시와 같이 예측하기 힘든 다양한 소비자가 사용합니다. 이러한 메모리 일부는 즉시 사용 가능(free) 또는 확보 가능(freeable)합니다. |
다수 테이블 관련 캐시 최적화
테이블 수가 많은 워크로드와 특히 관련이 캐시가 두 가지 있습니다. 이러한 캐시를 잘못 구성하면 잠재적으로 성능 및 안정성 문제가 발생할 수 있습니다.
테이블 캐시(또는 테이블 오픈 캐시)는 사용자 활동의 결과로 열린 테이블의 핸들러 구조를 저장합니다. 테이블은 각 세션별로 독립적으로 열립니다. 따라서 동일한 테이블에 액세스하는 여러 개의 동시 세션이 있는 경우 캐시는 해당 테이블에 대해 여러 항목을 포함할 수 있습니다. Aurora에서는 r4 클래스의 DB 인스턴스에 대해 이 캐시의 기본 크기를 6,000개의 오픈 테이블로 늘렸습니다. 하지만 이는 소프트 한도입니다. 이 캐시는 SQL 문과 관련된 테이블 수(및 해당 테이블의 파티션 수)에 따라 상당한 메모리를 소비하게 될 수 있습니다. 이러한 영향은 워크로드가 데이터베이스에서 실행하고 있는 동시 세션 수에 의해 증폭됩니다.
테이블 정의 캐시는 메모리에서 일반적으로 액세스되는 테이블에 대한 테이블 정의(스키마, 메타데이터)를 저장합니다. 테이블이 활발하게 사용될수록 테이블 정의를 캐시하는 것이 좋습니다. Aurora에서는 r4 클래스의 DB 인스턴스에 대해 이 캐시의 기본 크기를 최대 20,000개의 정의를 저장하도록 늘렸습니다. 따라서 이 캐시는 중요한 메모리 소비자가 될 수 있습니다. 수십만 개의 테이블을 사용하는 워크로드의 경우, 테이블 대부분이 활성 상태라면 이 캐시 크기를 기본 값 이상으로 늘릴 수 있는 혜택이 있습니다. 이 캐시 크기 또한 소프트 한도입니다. MySQL 데이터베이스 엔진은 상위-하위 외래 키 관련 테이블에 대한 테이블 정의를 제거하지 않습니다. 그러므로 캐시의 총 크기는 캐시 크기 한도를 초과할 수 있습니다.
따라서 효율적인 메모리 사용은 주어진 크기의 인스턴스로 Aurora 클러스터에서 운영할 수 있는 테이블 수를 실질적으로 제한할 수 있습니다. 이러한 캐시 공간을 줄이기 위해서는 이를 수용할 수 있도록 더 큰 DB 인스턴스 클래스를 사용해야 할 수 있습니다. 또는 이를 벌충하기 위해 쿼리 캐시 또는 버퍼 풀에 할당되는 메모리 양을 줄여야 할 수 있습니다. 이렇게 줄이면 다른 방식으로 워크로드 성능에 영향이 미칠 수 있습니다. 메모리가 작업 데이터 세트를 충족할 수 없기 때문입니다. 하지만 “너무 많은” 테이블이 정확히 몇 개를 말하는지 찾아내기가 어렵습니다. 다음 예제에서 이러한 효과를 더 잘 확인할 수 있습니다.
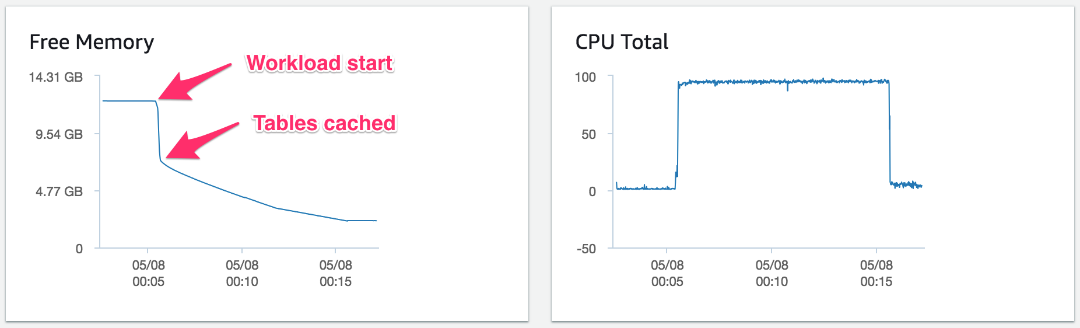
아래 차트는 테이블이 1,000개인 데이터베이스에 대해 40개의 동시 연결을 사용하여 수행된 sysbench 읽기 및 쓰기 OLTP 테스트의 향상된 모니터링 지표를 통해 보고된 free 메모리를 보여줍니다. 이 워크로드는 61GB의 메모리가 탑재된 Aurora MySQL 5.6 호환 db.r4.2xlarge DB 인스턴스(인기 있는 인스턴스 클래스)에서 단 10분 동안 실행되었습니다.
이 테스트의 경우 다음 명령을 사용해 테스트 실행 전에 데이터베이스와 테이블을 준비합니다.
이 시스템의 free 메모리는 테스트가 시작될 때 갑자기 12.2GB에서 5GB가 하락하고 CPU 리소스는 테스트를 거치면서 거의 모두 고갈됩니다. MySQL 커뮤니티 에디션과는 달리 Aurora는 버퍼 풀을 사전에 할당하며 이전 테스트에서 이미 워밍 상태였습니다. 비교적 적은 수의 활성 테이블(1,000개)과 총 동시 연결(40개)로 테스트를 수행했습니다. 메모리 소비는 테이블 캐시와 많은 수의 활성 테이블이 관련되어 있을 때 각 연결에 대한 증폭 효과로 인해 주로 발생합니다.
DB 인스턴스 파라미터 그룹의 table_open_cache 파라미터는 테이블 캐시 크기를 제어합니다. 기본적으로 이 파라미터는 다음 수식을 사용하여 설정됩니다.
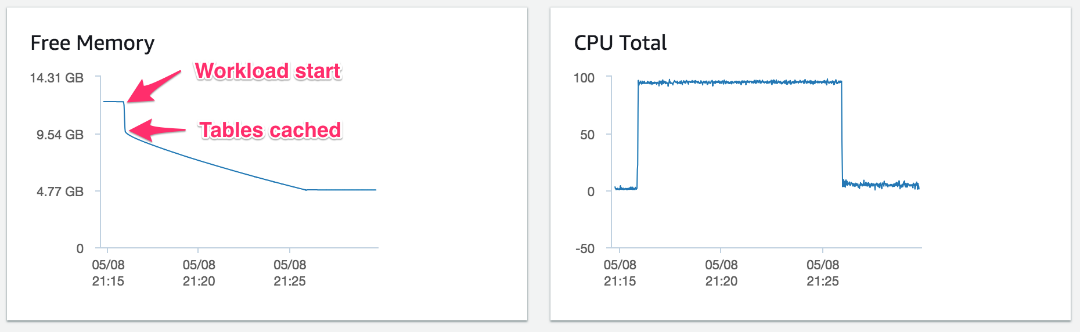
비교를 위해 다음 차트가 유사한 테스트를 보여줍니다. 유일한 차이점은 이 테스트에서 액세스하는 테이블이 500개뿐이라는 것입니다. 여기에서 시스템의 free 메모리는 테스트가 시작될 때 갑자기 12.2GB에서 약 2.5GB가 하락합니다.
다음 예제는 많은 수의 테이블이 사용될 때 테이블 정의 캐시의 영향을 보여줍니다. 이 테스트에서 예제 워크로드는 100,000개의 간단한 테이블을 생성하며, 각 테이블에는 자동 증가 정수 기본 키, 타임스탬프 열, 부동 소수점 열, 2개의 짧은 문자열 열이 있습니다. 이 테스트에서는 15.25GB의 메모리가 탑재된 Aurora MySQL 5.7 호환 db.r4.large DB 인스턴스에서 실행되는 단일 연결을 사용하여 하나의 행을 간단한 테이블 각각에 삽입합니다. Aurora 클러스터에서 실행되는 다른 활동은 없으며, 클러스터는 빈 상태에서 시작됩니다.
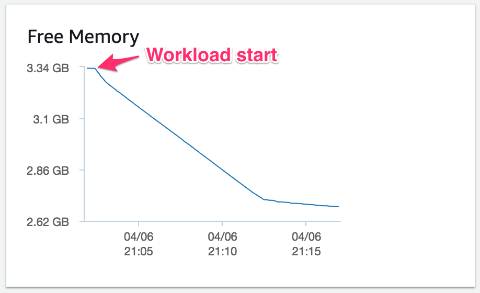
워크로드가 증가함에 따라 free 메모리가 어떻게 감소하는지 확인할 수 있습니다. 캐시 한도에 도달하면서 free 메모리가 안정화되며, 전체적으로 700MB의 메모리가 추가적으로 사용되고 이는 주로 테이블 정의 캐시에 사용됩니다.
DB 인스턴스 파라미터 그룹의 table_definition_cache 파라미터는 테이블 정의 캐시의 크기를 제어합니다. 기본적으로 이 파라미터는 다음 수식을 사용하여 설정됩니다.
결론적으로 실제로 통합할 수 있는 테이블 수는 몇 가지 요인에 따라 달라집니다. 이러한 요인은 활발하게 사용되는 테이블 수, 가용 메모리 양, 지원해야 하는 동시 연결 수입니다.
높은 데이터베이스 리소스 사용률을 최적화하는 방법
이 게시물의 앞부분에서 더 큰 테이블 또는 더 많은 수의 테이블이 CPU 또는 메모리와 같은 서버 리소스 사용률에 영향을 미친다는 것을 설명했습니다. 하지만 워크로드 통합 자체가 사용률을 높입니다. 데이터베이스 샤드 수가 감소하면, 나머지 데이터베이스 샤드마다 더 많은 동시 연결이 설정될 수 있습니다. 각 통합 데이터베이스는 더 많은 작업을 수행하고 읽기 및 쓰기 쿼리 볼륨이 증가합니다.
Amazon Aurora for MySQL에는 내부 서버 연결 풀링 및 스레드 멀티플렉싱이 함께 제공되므로, 수천 개의 동시 연결을 처리할 때 경합을 줄이고 확장성을 개선할 수 있습니다. 최대 16,000개의 동시 연결을 허용하도록 각 Aurora DB 인스턴스를 구성할 수 있습니다. 하지만 워크로드 및 DB 인스턴스 클래스 선택에 따라 실제 최대 값이 이보다 적은 수로 제한될 수 있습니다.
각 연결, 세션 및 스레드는 현재 실행 중인 특정 SQL 문을 기반으로 다양한 버퍼, 캐시, 기타 메모리 구조에서 다양한 양의 메모리를 소비합니다. 이러한 소비는 결정적이지 않으며, 이 블로그 게시물의 앞부분에서 설명한 다른 구조들과 마찬가지로 같은 양의 가용 메모리를 두고 경쟁합니다. 효과적인 연결 관리 및 규모 조정에 대한 모범 사례를 이해하려면 연결 관리를 위한 Amazon Aurora MySQL DBA 핸드북 백서가 훌륭한 리소스입니다. 더 크고 더 높은 처리량의 워크로드에 대한 연결 사용률을 최적화하는 데 도움이 되는 유용한 조언이 포함되어 있습니다.
요약
Amazon Aurora with MySQL Compatibility를 여러 데이터베이스 워크로드 통합을 위한 솔루션으로 고려할 때 여러 가지 요인이 개입하게 됩니다. 완전한 목록은 아니지만, 앞서 설명한 항목에는 이러한 통합을 구현하는 고객을 지원할 때 보게 되는 공통된 고려 사항이 포함되어 있습니다. 모든 워크로드가 다르므로, 통합에 대한 실질적인 제한은 사례마다 다릅니다.
모범 사례는 프로덕션 규모의 기본값에서 구성 변경 사항을 철저하게 테스트하고 성능과 안정성에 수량화할 수 있는 긍정적인 영향이 미치는 경우에만 이를 구현하는 것입니다. 이 모범 사례는 MySQL 커뮤니티 에디션에서 구성을 가져올 때 특히 중요합니다. Aurora는 같은 방식으로 동작하지 않을 수 있기 때문입니다. 워크로드 통합 프로젝트를 실행하는 방법에 대한 자세한 내용은 AWS 데이터베이스 블로그의 Reduce Resource Consumption by Consolidating Your Sharded System into Aurora 게시물을 참조하십시오.
'Cloud > AWS' 카테고리의 다른 글
| NFS Performance Test with Amazon EFS (0) | 2018.09.15 |
|---|---|
| 어떻게 메인프레임을 AWS 클라우드로 이전하나요? (0) | 2018.09.10 |
| AWS CDK 개발자 미리보기 (0) | 2018.08.29 |
| 아마존의 14가지 리더십 원칙 (0) | 2018.08.12 |
| Amazon EC2 인스턴스 내부 네트워크 대역폭 상향 (0) | 2018.02.08 |